编译原理ch1
Ch1 引论
编译器的结构
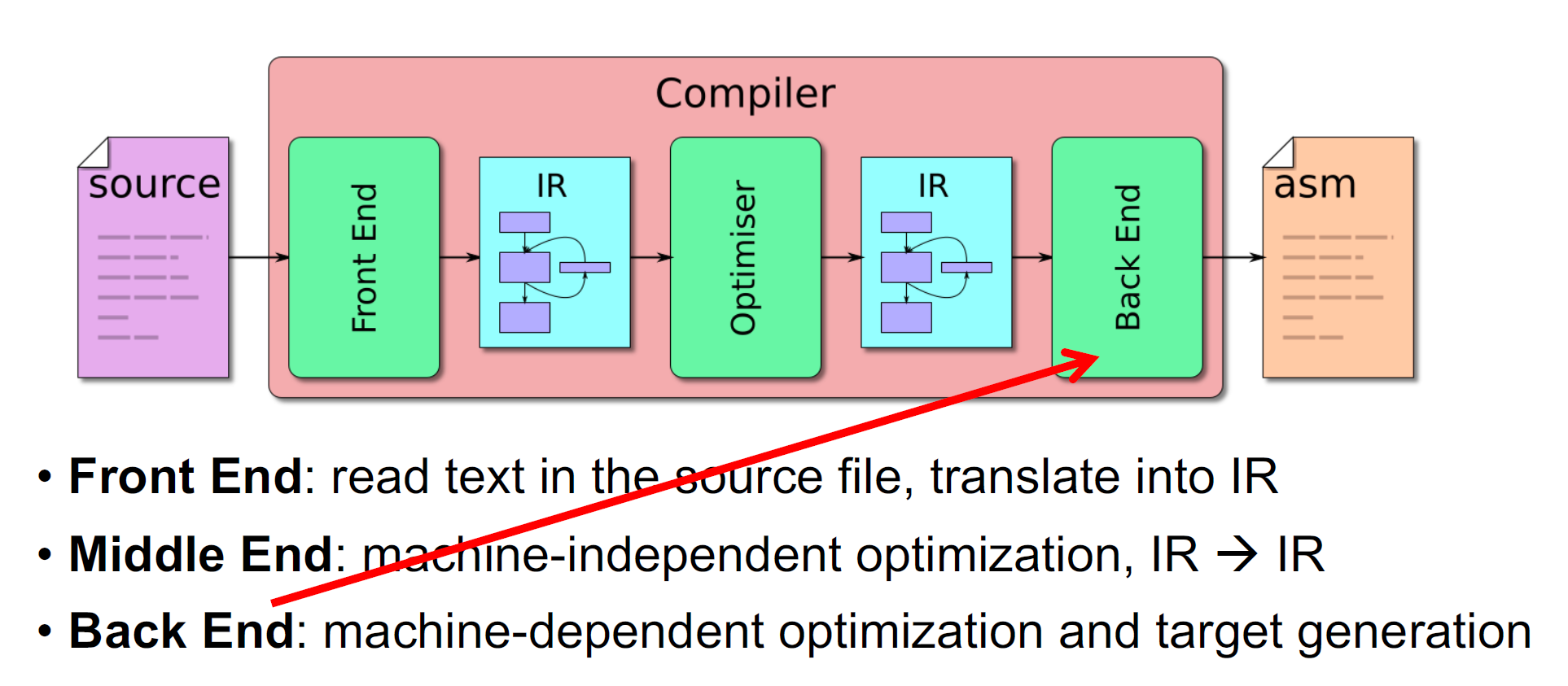
分解得更细一些:
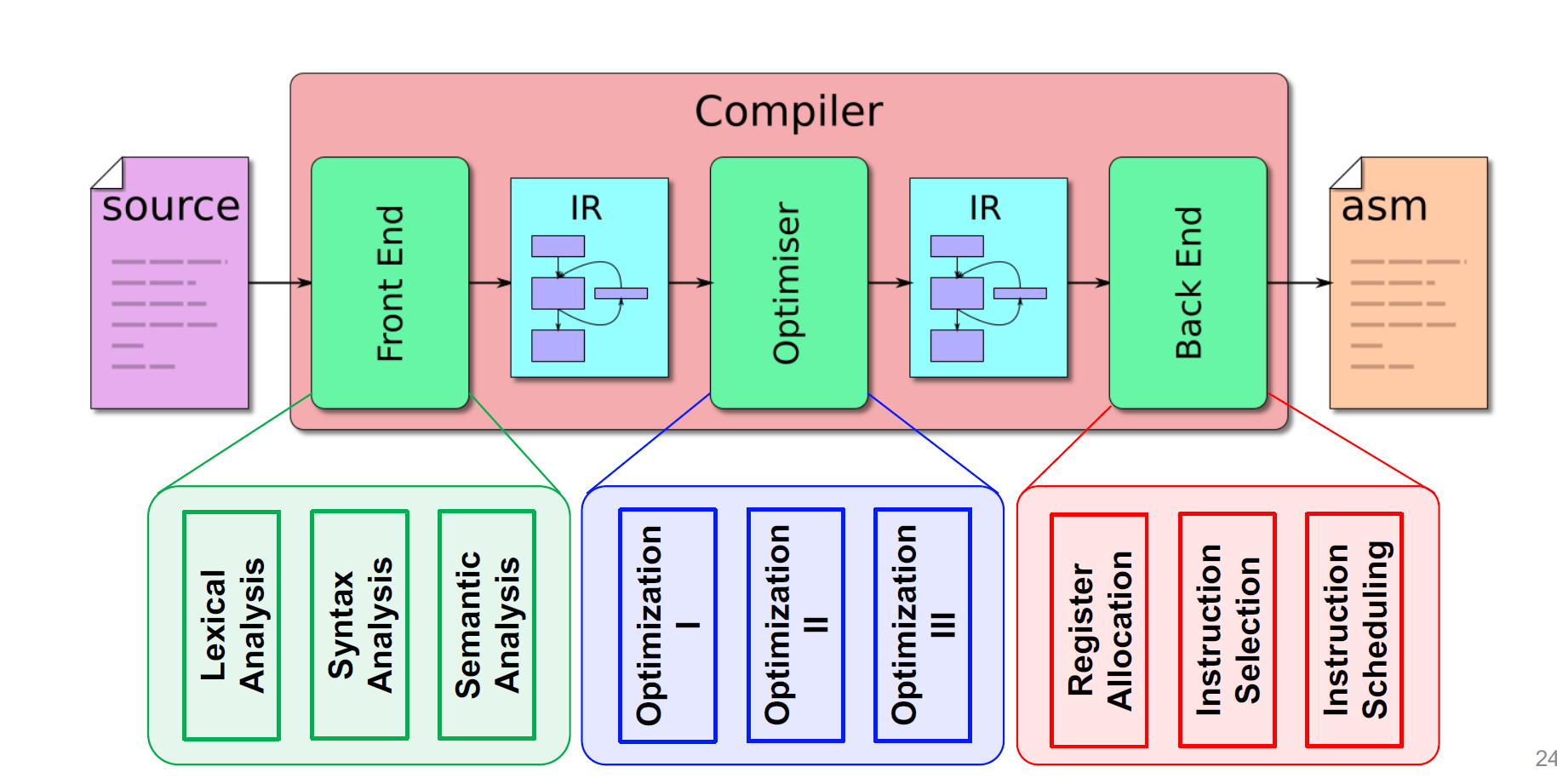
前端(Front End):把源程序分解成为多个组成要素,并在这些要素之上加上语法结构。然后,它使用这个结构来创建该源程序的一个中间表示。
词法分析(Lexical Analysis) $\rightarrow$ 语法分析(Syntax Analysis) $\rightarrow$ 语义分析(Semantic Analysis)
Lexical Analysis
Find lexemes(词素) according to patterns, and create tokens
Lexeme – a character string
Pattern – regular expression (lexical errors if no patterns matched)
Token – <token-class, attribute>
attribute 将同一类 token 区分开来,它指向符号表中关于这个词法单元的条目
Syntax Analysis
创建抽象语法树 (AST)
Semantic Analysis
使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。它同时也收集类型信息,并把这些信息存放在语法树或符号表中,以便在随后的中间代码生成过程中使用。
类型检查
IR Generation
根据语法树生成机器无关中间表示
三地址码
Middle End:优化
Machine-independent optimizations, working on IR
IR好处:
- vs. source code: IR provides standard form, easier to process
- vs. machine code: IR provides machine-independent abstraction with source information
后端(Back End):代码生成
将 IR 翻译为机器码
执行机器相关优化
包含:寄存器分配,指令安排
一些概念
静态(static):编译时决定
动态(runtime):运行时决定
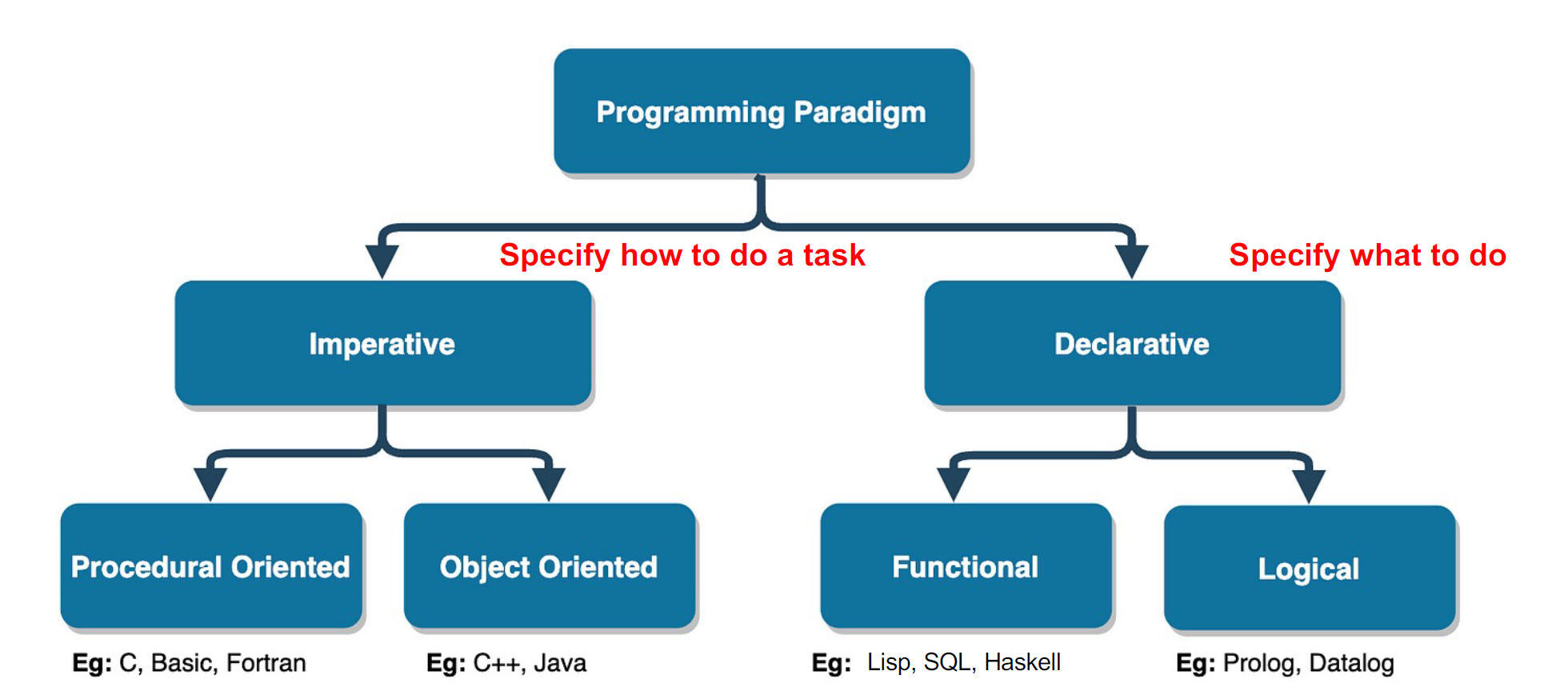
编程范式:
强类型与弱类型:is about how strictly types are distinguished (e.g. whether the language can do an implicit conversion from strings to numbers).
参数传递:值传递(Call by value)和引用传递(Call by reference)