计组笔记
计组复习
NJU SE 2024年计组知识点概要、作业错题、大题做法参考
1 计算机系统概述
通用电子数字计算机 (general purpose electronic digital computer)
- 通用:不是一种专用设备
所有计算机在给予足够时间和容量存储器的条件下 都可以完成同样的计算
当希望完成新的计算时 不需要对计算机重新设计- 电子(非机械):采用电子元器件
- 数字(非模拟):信息采用数字化的形式表示
组织、结构
组织:对编程人员不可见,包括控制信号、存储技术。例如:乘法指令的内部实现
结构:对编程人员可见,包括指令集、位数。例如:是否提供乘法指令
计算机的演变:第一代:真空管;第二代:晶体管;第三代及以后:集成电路
冯诺依曼结构
- 计算机由运算器、存储器、控制器、输入设备、输出设备组成
(存储程序思想)
指令和数据以同等地位存放在存储器内,并可按地址访问
(可以按指令周期的不同阶段来区分)
指令和数据均用二进制表示
摩尔定律
更小的尺寸带来更多灵活性和可能性;
由于单个芯片的成本几乎不变,计算机逻辑电路和存储电路的成本显著下降;
减少了对电能损耗和冷却的要求;
集成电路上的内部连结比焊接更可靠,芯片间的连接更少
性能评价
- CPU :速度
- 存储器:速度,容量
- I/O 速度:容量
计算机设计的主要目标:提高 CPU 的性能
系统时钟
- 时钟频率 / 时钟速度 (单位 Hz)
- 时钟周期 / 周期时间(单位:s ):执行每次最基本操作的时间
指令执行(重要)
- CPI (Cycle per Instruction)
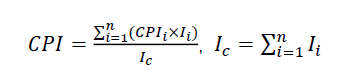
- 每秒百万条指令 (Million Instructions Per Second, MIPS)
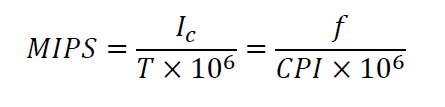
- 每秒百万条浮点操作 (Million Floating Point Operations Per Second, MFLOPS)
- CPI (Cycle per Instruction)
基准程序
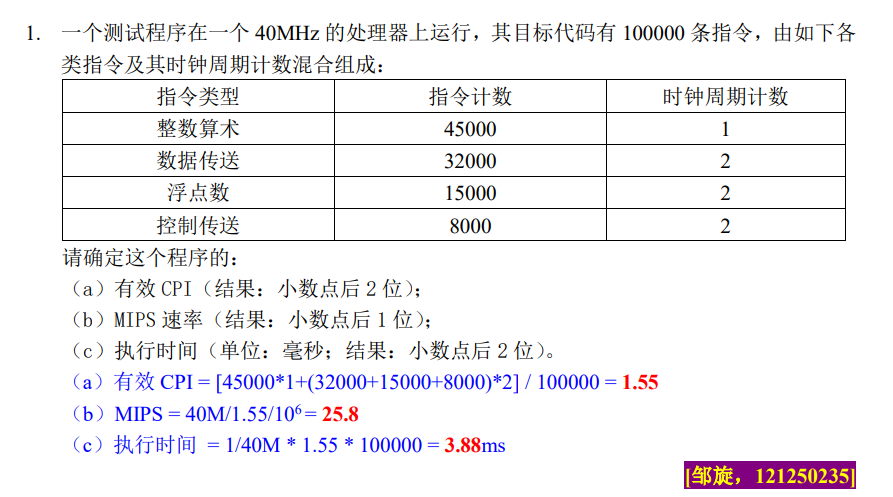
习题1
CPI 相关的计算

2 计算机的顶层视图
六个问题
- CPU 的频率不能无限提高
改进 CPU 芯片结构 - 内存墙
使用 cache - CPU 等待 I/O 传输数据
采用中断机制 - 兼顾存储容量、速度和成本
使用金字塔型的存储器层次结构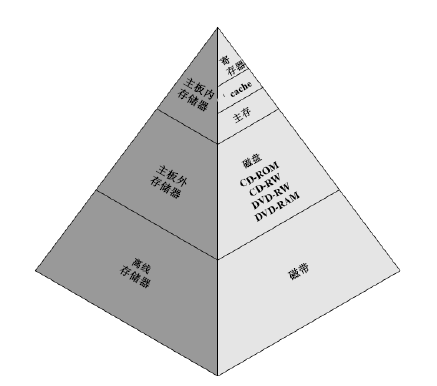
- I/O 设备传输速率差异大
采用缓冲区和改进 I/O 操作技术 - 计算机部件互连复杂
使用总线
3 数据的机器级表示
二进制编码原因
多种物理器件可以表示两种稳定的状态,用于表示0和1;
二进制的编码和运算规则简单;
1和0可以表示逻辑上的真和假
使用补码的原因
原码、反码、移码在进行加法运算时都会造成不必要的硬件需求,因此目前计算机中普遍使用补码
使用 NBCD 码的原因
浮点运算的限制:精度限制、转换成本高;
应用需要:长数字串的计算:会计
4 数据校验码
差错(Error):数据在计算机内部进行计算、存取和传送过程中,由于元器件故障或噪音干扰等原因,会出现差错。
硬故障:永久性的物理故障,由恶劣的环境、制造缺陷和旧损引起
软故障:随机非破坏性事件,由电源问题或α粒子引起
奇偶校验码


优点:代价低,只需要1位额外数据,计算简单
缺点:不能发现出错位数为偶数的情形;不能纠错
适用:对较短长度(1B)的数据进行检错
海明码
将数据分成几组 对每一组都使用奇偶校验码进行检错(具体方法是把校验位放在二进制只有一个 1 的位,即二的幂次位,再将位数的二进制表示中按位与非0的位加入组中,这样就达成了位的编码)
优点:1位错误时可以纠错
缺点:额外成本很大;要求把数据分为字节
循环冗余校验(CRC)
适用于以流格式存储和传输大量数据
用数学函数生成数据和校验码之间的关系
习题2

5 整数运算
加法部件
全加器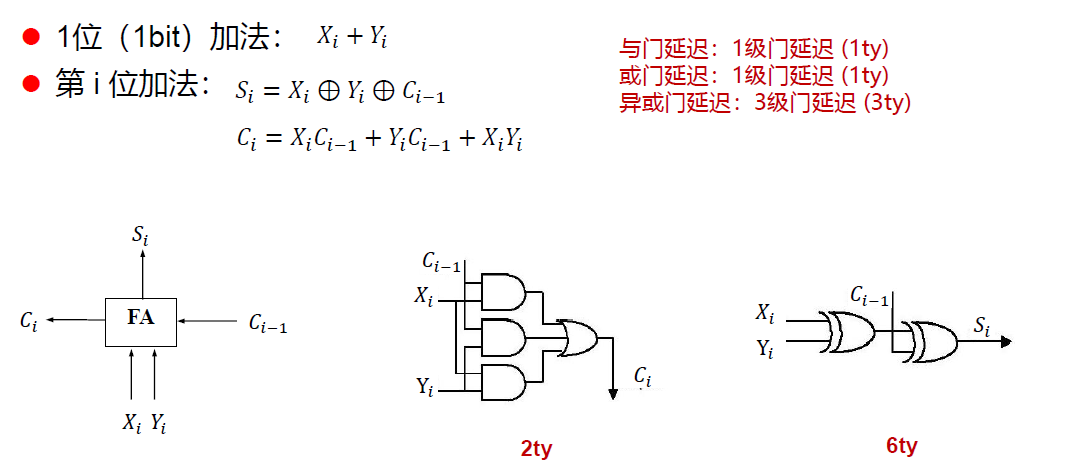
串行进位加法器(行波进位加法器)
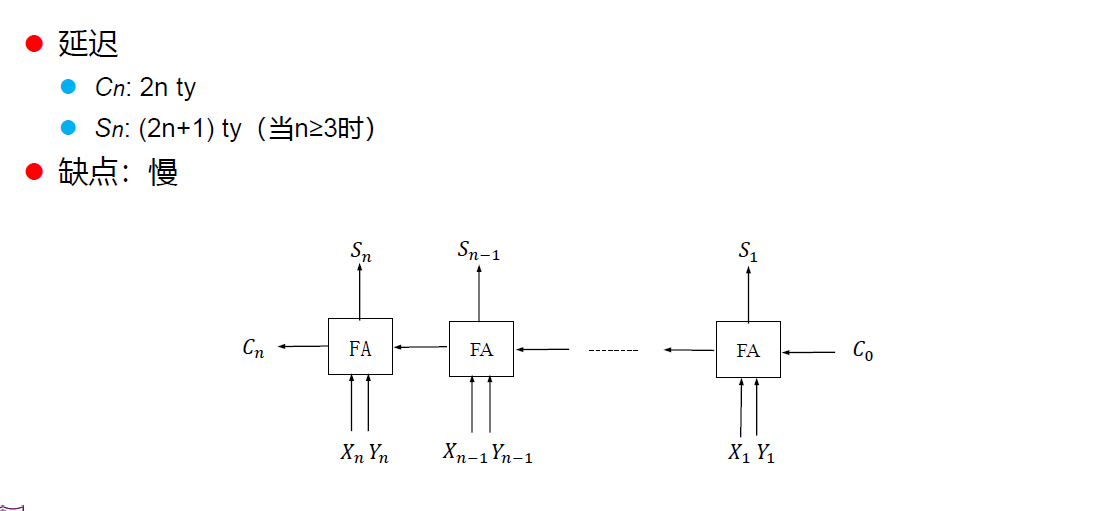
先行进位
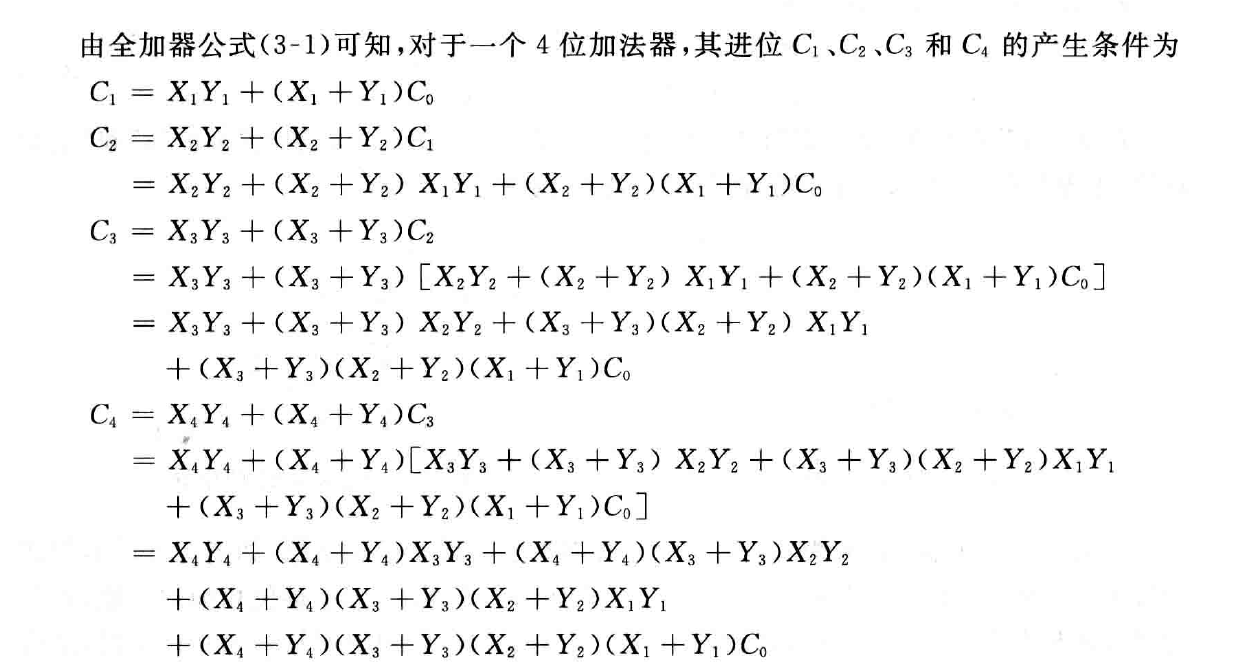
以上公式表明: 每个进位表达式中都含有 $X_i+Y_i$ 和 $X_iY_i$ ,因此定义两个辅助函数如下:
$$
\begin{align*}
P_i &= X_i+Y_i\
G_i &= X_iY_i
\end{align*}
$$
$P_i$ 称为进位传递函数,$G_i$ 称为进位生成函数。
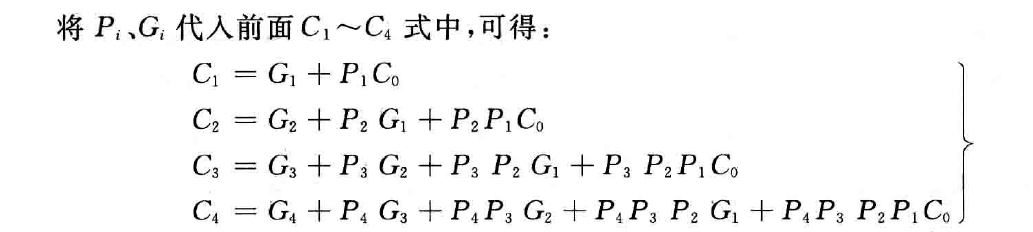
由此可见,$C_i$ 仅与 $X_i,Y_i,C_0$ 有关,相互之间的进位并没有依赖关系。只要 $X_1\sim X_4,Y_1\sim Y_4,C_0$ 同时到达,就可以近乎同时生成 $C_1\sim C_4$,并同时生成各位的和。
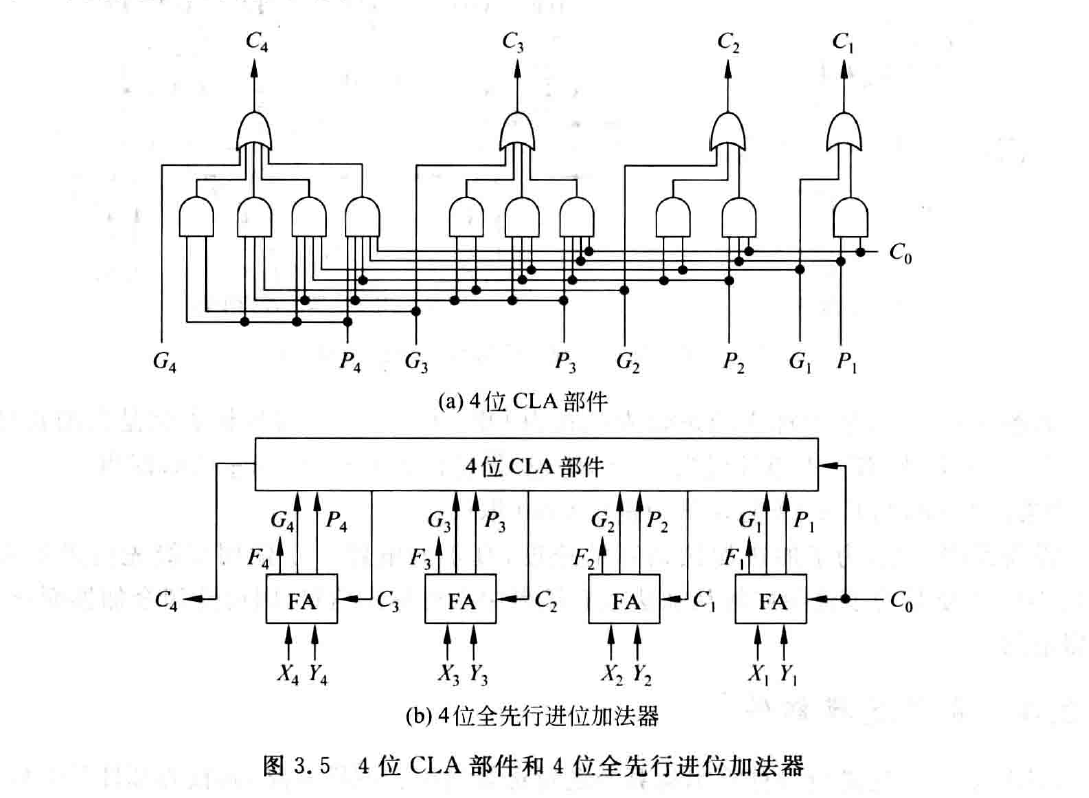
实现上述逻辑的电路称为先行进位(超前进位)部件(Carry Lookhead Unit),简称 $CLA$ 部件。
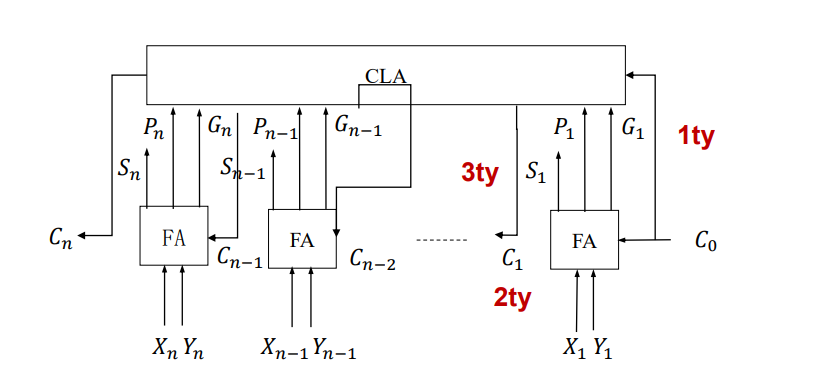
延迟:6 ty
全先行进位加法器:速度快;但随着位数增加电路会越来越复杂
部分先行进位加法器:取得计算时间和硬件复杂度的权衡
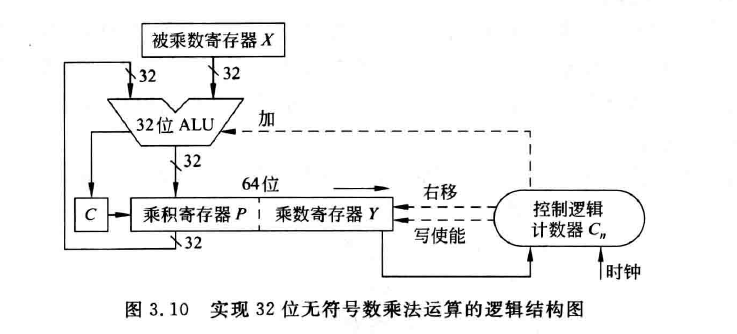
乘法
原码乘法
算法:

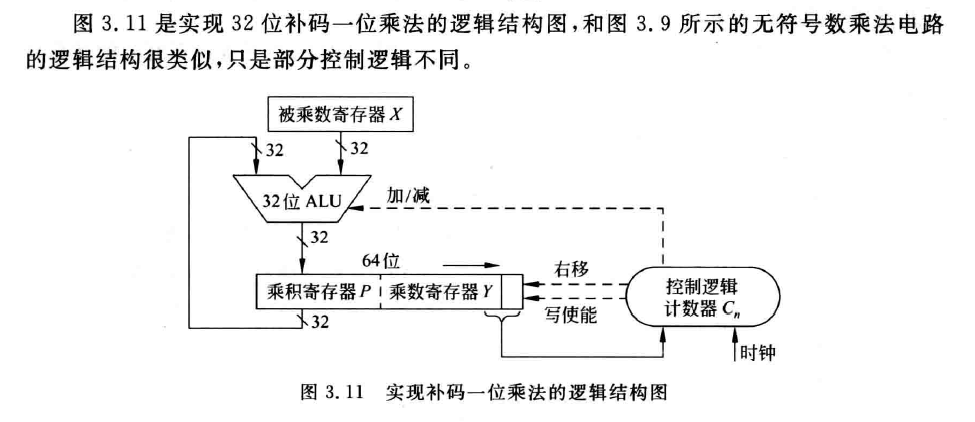
布斯算法(补码乘法)
- 乘数最低位增加辅助位 $Y_{-1}=0$。
- 根据 $Y_iY_{i-1}$ 的值,决定加减
- 每次加减后,算数右移一位,得到部分积
- 重复第2,3步 $n$ 次,结果得到 $[x\times y]_c$
除法
原码除法
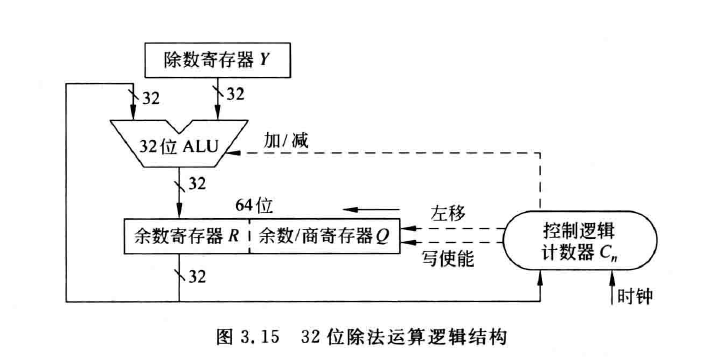
分为是否恢复余数
补码类似
6 浮点数运算
加减法
必须确保两个操作数具有相同的指数值
$$
X\pm Y=(X_S\times B^{X_E-Y_E}\pm Y_S)\times B^{Y_E}\
X_E\leq Y_E
$$
步骤:
- 检查0
- 对阶:小阶向大阶看齐,阶小的那个数尾数右移,右移的位数等于两个阶的差的绝对值
- 尾数加减
- 规格化,舍入
乘除
先判0,规格化,溢出判断
乘除无需对阶
乘法从阶值的和中减去一个偏移量,有效值相乘
尾数规格化:对于规格化整数相乘,一定满足乘积绝对值大于等于1,小于4,
只需要右规
除法:阶值相减,加上一个偏移量,有效值相除
精度考量:保护位
- 寄存器的长度几乎总是大于有效值位长与一个隐含位之和
- 保护位用0填充,用于扩充有效值的右端
习题3
略
7 二进制编码的十进制数运算

8 内部存储器
**存储器(Memory)**由一定数量的单元构成,每个单元可以被唯一标识,每个单元
都有存储一个数值的能力
地址:单元的唯一标识符(采用二进制)
地址空间:可唯一标识的单元总数
寻址能力:存储在每个单元中的信息的位数
大多数存储器是字节寻址的,而执行科学计算的计算机通常是 64 位寻址的
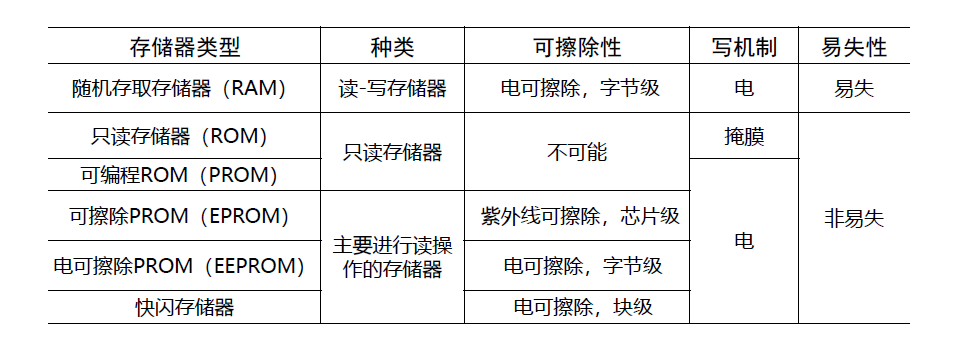
RAM:随机存取存储器
分为 DRAM、SRAM
DRAM 和 SRAM 的对比:
相同点:易失(volatile),需要电源供电来保持位值
不同点:
DRAM比SRAM具有更简单、更小的位元,但要求能够刷新的电路
DRAM比相应的SRAM密度更高、价格更低
SRAM通常比DRAM快
DRAM通常满足大容量存储器的需求,SRAM一般用于高速缓存,DRAM用于主存
高级的DRAM架构:
问题:
传统的DRAM芯片受到其内部架构和处理器内存总线接口的限制
传统DRAM是异步的
类型:
- 同步 DRAM,Synchronous DRAM, SDRAM
- 双速率 SDRAM,Double Data Rate SDRAM(DDR SDRAM / DDR)
ROM:只读存储器
特性:非易失;可读但不可写
应用:微程序设计、库子程序、系统程序、函数表
问题:
无出错处理机会,如果有一位出错,整批的ROM芯片只能报废;
用户无法写入数据,唯一的数据写入机会在出厂时完成
PROM:可编程ROM
特性:非易失;只能被写入一次,写入内容用电信号,通过“编程”实现
与ROM的对比:
PROM提供了灵活性和方便性
ROM在大批量生产领域仍具有吸引力
主要进行读操作的存储器
特性:非易失;写操作较读操作困难
应用:读操作比写操作频繁得多的场景
类型:EPROM、EEPROM、快闪
EPROM:
特性:光擦除,电写入
与PROM对比:EPROM更贵,但具有可多次改写的优点
EEPROM:
特性:可以随时写入而不删除之前的内容;只更新寻址到的一个或多个字节;写操作每字节需要几百微秒
与EPROM对比:EEPROM更贵,且密度低,支持小容量芯片
快闪存储器:
特性:
电可擦除:与EEPROM相同,优于EPROM
擦除时间为几秒:优于EPROM,低于EEPROM
可以在块级擦除,不能在字节级擦除:优于EPROM,不如EEPROM
达到与EPROM相同的密度:优于EEPROM
价格和功能介于EPROM和EEPROM之间

内存的刷新策略:
集中式刷新:
方式:停止读写操作,刷新每一行
缺点:刷新时无法操作内存
分散式刷新:
方式:每个存储周期内,读写操作完成时进行刷新
对集中式的改进:用户不会感受到内存停止
缺点:会增加每个存储周期的时间
异步刷新:
方式:每行各自以64ms间隔刷新;两个时间间隔内保证每一行被刷新一次
优点:刷新不需要占用读写时间,效率高,常用
内存的模块组织策略

大端序、小端序
- 在两种策略中每个数据项有同样地址
- 在任何一个给定的多字节值中,小端的字节排序是大端的反序,反之亦然
- 端序不影响结构中数据项的次序
习题4
刷新
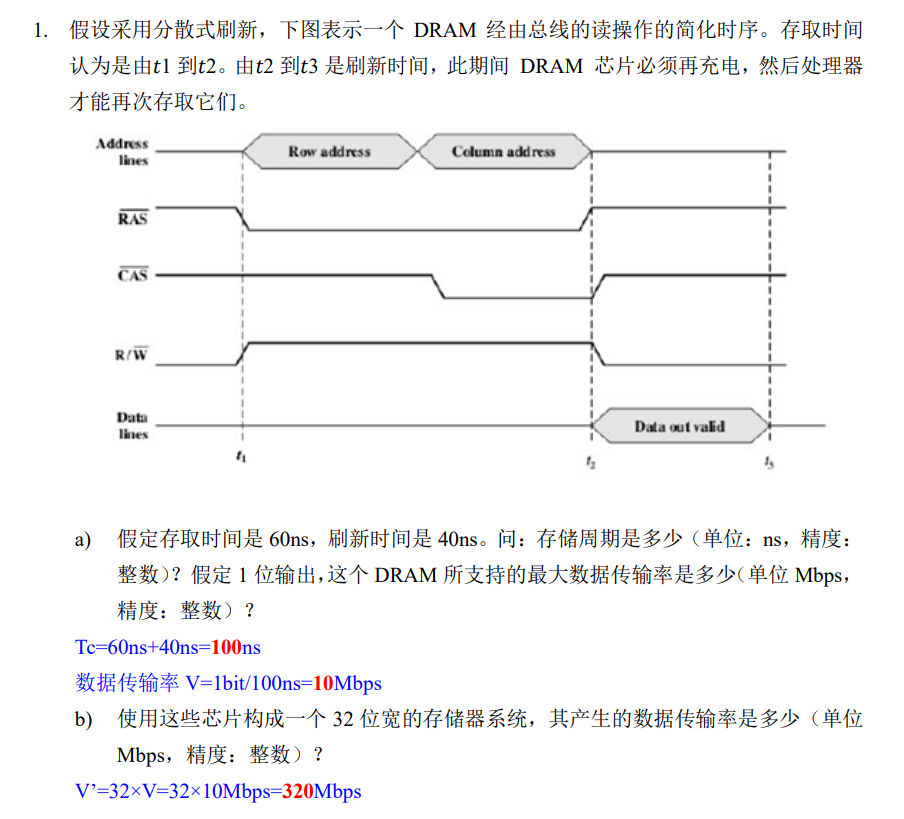
按行刷新

DRAM的引脚问题


9 Cache
高速缓冲存储器
程序访问的局部性原理
时间局部性:在相对较短的时间周期内,重复访问特定的信息
空间局部性:在相对较短的时间周期内,访问相邻位置的数据
顺序局部性:当数据被线性排列和访问(一维数组等)时,空间局部性的特殊情况
扩大Cache容量的好处与局限:
好处:增加了命中率
局限:增大了Cache的开销和访问时间

映射策略
直接映射:
关联度:1
优点:简单、快速映射、快速检查
缺点:抖动现象:如果一个程序重复访问两个需要映射到同一行中且来自不同
块的字,则这两个块不断地被交换到 cache 中, cache 的命中率将会降低适用:大容量的Cache
关联映射:
关联度:C
优点:避免抖动
缺点:实现起来较为复杂;搜索代价大
适用:容量较小的Cache
组关联映射:
关联度:K
优点:结合了直接映射和关联映射的优点
缺点:结合了直接映射和关联映射的缺点
适用:容量中等的Cache
三种映射策略的比较:
关联度越低,命中率越低,判断是否命中的时间越短,标记额外空间越小。
命中率:直接映射<组关联映射<关联映射
命中时间:直接映射<组关联映射<关联映射
标记长度:直接映射<组关联映射<关联映射
替换算法
通过硬件实现
LRU实现:对于2路组关联映射,每行包含一个USE位
FIFO实现:时间片轮转法或环形缓冲技术
LFU实现:每一行设置一个计数器
随机替换实现:随机替换,性能上只稍逊于其他算法

写策略
写直达:
优点:确保主存和Cache的内容总是一致的
缺点:产生大量的主存访问,减慢写操作
写回法:
优点:减少了主存访问的次数
缺点:部分主存数据可能不是最新的:I/O模块存取时可能会无法获得最新的数据,为解决该问题会使得电路设计更加复杂且有可能带来性能瓶颈
行大小与命中率的关系:先增后减
习题5
计算

命中率(很爱考)

结合程序的分析

10 外部存储器
用于存储不经常使用的、数据量较大的信息
非易失

磁盘
磁盘是由涂有可磁化材料的非磁性材料(基材)构成的圆形盘片
磁盘使用玻璃基材的优势:
- 改善磁膜表面的均匀性,提高可靠性
- 减少表面瑕疵,从而减少读写错误
- 能够支持磁头较低的飞行高度
- 更高的硬度,转动时更稳定
- 更强的抗冲击和抗损伤能力
磁头的数量:
- 单磁头:读写公用同一个磁头(软盘,早期硬盘)
- 双磁头:读写分别用一个磁头(当代硬盘)
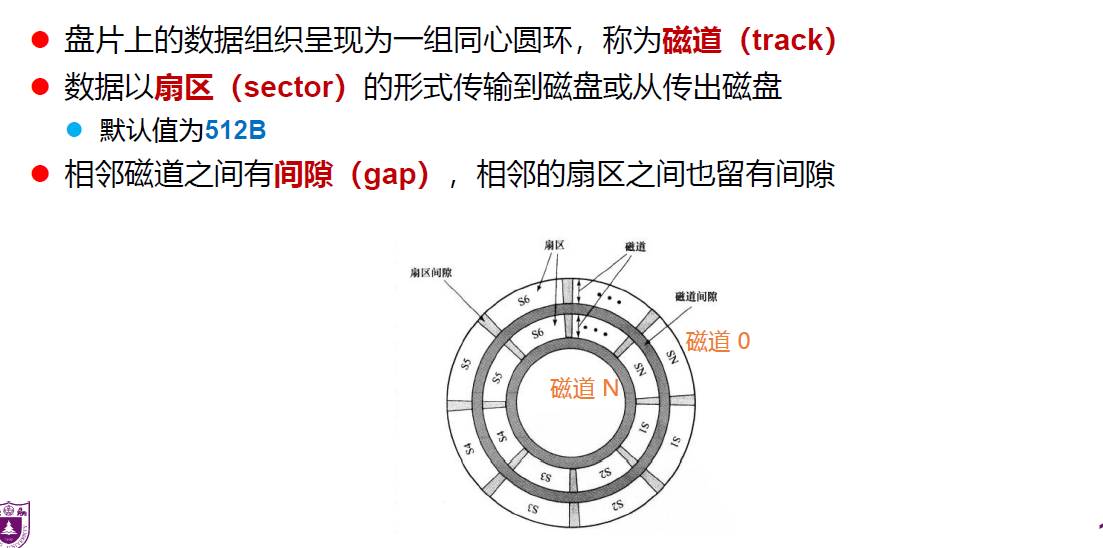
扇区划分
恒定角速度:
增大盘片区域上信息位的间隔,是磁盘能以恒定角速度扫描信息
优点:能以磁道号和扇区号直接寻址各个数据块
缺点:存储容量受到最内侧磁道的最大数据密度的限制
多带式记录:
将盘面划分为多个同心圆区域,每个区域各磁道的扇区数量相同;外侧磁道的扇区数多于内侧磁道
优点:提升存储容量
缺点:需要更复杂的电路

I/O访问时间(常考大题)

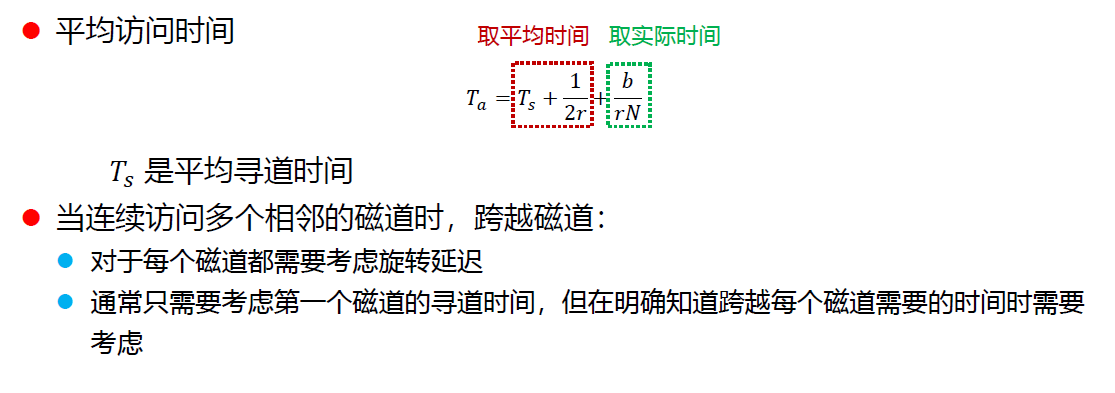
磁盘调度算法
先来先服务(FCFS):
优点:公平简单
缺点:如果有大量分散的请求会性能不佳
最短寻道时间优先(SSTF):
优点:每次寻道时间最短(局部最优),平均寻道时间缩短
缺点:可能产生饥饿现象,尤其是位于两端的磁道请求
扫描/电梯(SCAN):
优点:性能较好,平均寻道时间较短,不会产生饥饿现象
缺点:只有到最边上的磁道才能改变磁头方向,对各个磁道响应时间不平均
循环扫描(C-SCAN):
优点:与SCAN算法相比:对各个磁道的响应频率平均
缺点:平均寻道时间比SCAN长
LOOK:
优点:减少了SCAN需要移动到边缘的额外时间
缺点:对新加入的任务不友好(尤其是边缘处的)
C-LOOK:
优点:减少了C-SCAN算法的时间
缺点:略慢于LOOK算法
光存储器
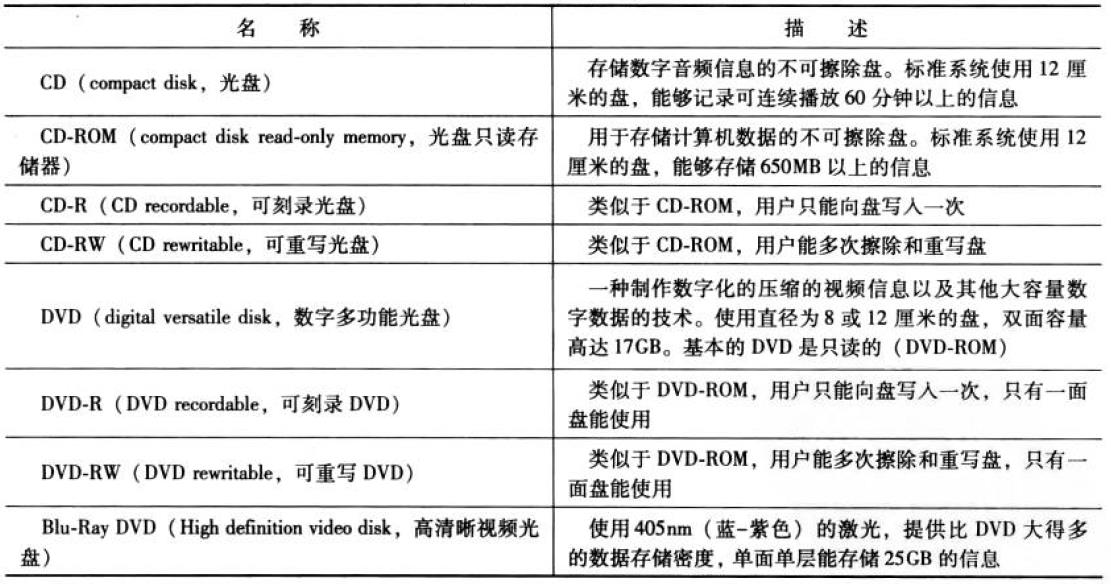
一些区别
CD和CD-ROM的优缺点:
优点:可以大规模复制;可以更换;CD-ROM比CD更耐用且有纠错功能
缺点:只读;存取时间比磁盘长得多
DVD vs CD:
DVD上的位组装更精密;DVD采用双层结构;DVD-ROM可以用两面记录数据
磁带和磁盘的区别:
读取:磁带采用顺序读取,磁盘采取直接读取
记录:磁带采用蛇形(串行)记录或并行记录,目前采取串行记录
U盘 vs 软盘、光盘:
U盘使用快闪存储器,体积小,容量大,非常方便,寿命长达数年
固态硬盘 vs 硬磁盘存储器:
抗震性好,无噪声,能耗低,发热量低
习题6
基础计算

数据传输率

寻道算法

11 磁盘冗余阵列(RAID)
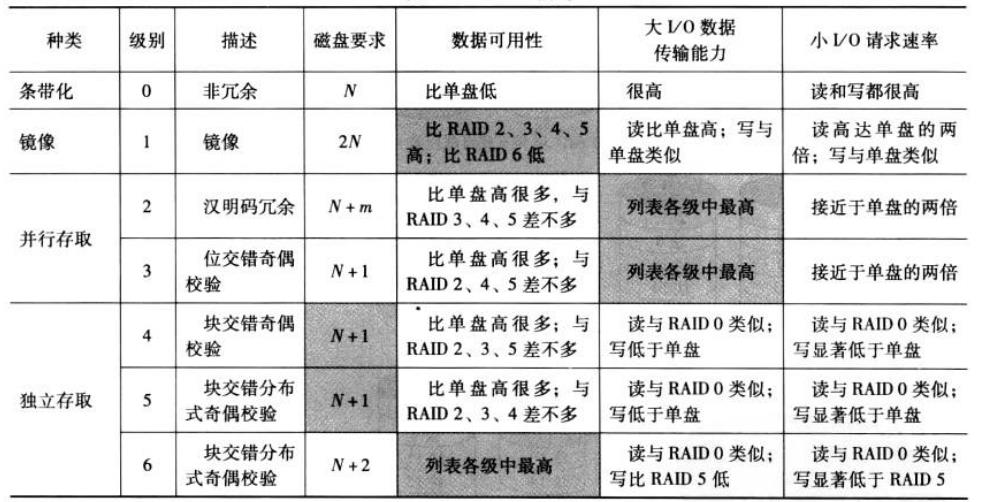
RAID0:
优点:将I/O负载分散,提高性能;无奇偶计算开销;设计简单易实现
缺点:只要有一个驱动器失效就会全部数据丢失
应用:任何要求高带宽的应用,如视频编辑、图像处理、应用压缩
RAID1:
优点:数据100%冗余,某些环境下能承受多个驱动器同时失效;最简单RAID子系统设计
缺点:磁盘数开销最大
应用:任何要求高可用性的应用,如统计、工资单、财务
RAID10:先做RAID1,再做RAID0
RAID01:先做RAID0,再做RAID1,两者主要区别在于对磁盘损坏的容错能力(类比逻辑上的与门和或门)
RAID2:
优点:可能有极高的数据传输率;数据传输率要求得越高,数据盘对ECC盘的比值越好;控制器实现比RAID3,4,5简单
缺点:短字长时很低效;冗余盘成本很高;只适用于多磁盘易出错环境
应用:无商品实现的存在/无商业化应用
RAID3:
优点:很高的读写传输率;磁盘失效时对吞吐率无显著影响;ECC对数据盘的低比率意味着高效率
缺点:最好情况下的事务率等于单盘的事务率;控制器设计相当复杂
应用:任何要求高吞吐率的应用,如直播、视频剪辑、图像处理、应用压缩
RAID4:
优点:很高的读数据事务率;ECC对数据盘的低比率意味着高效率
缺点:十分复杂的控制器设计;最差的写事务率和写聚集传输率;磁盘失效事件中,数据重构困难且低效
应用:无商品实现的存在/无商业化应用
RAID5:
优点:最高的读数据事务率;ECC对数据盘的低比率意味着高效率;好的聚集传输速率
缺点:最复杂的控制器设计;磁盘失效事件中,重构数据困难(和RAID1相比)
应用:用途最多的RAID级;用于各种服务器
RAID50:对多组RAID5彼此构成条带访问,性能更高但容量利用率更低
RAID6:
优点:数据故障容忍能力最高,能承受多个驱动器同时失效
缺点:较复杂的控制器设计;计算奇偶校验地址的控制器开销非常高
应用:丢失数据严重的应用
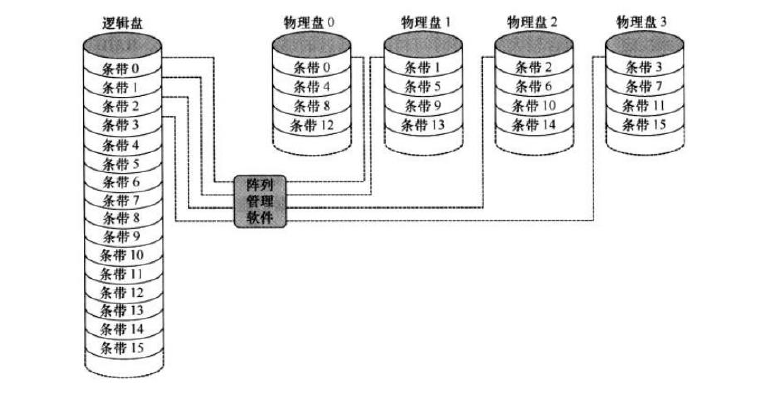
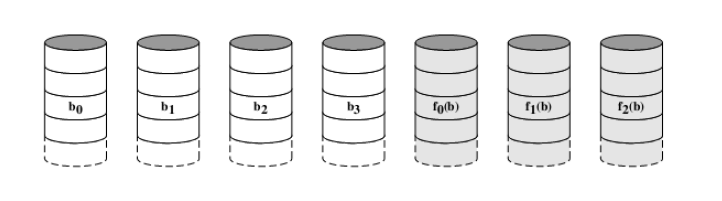
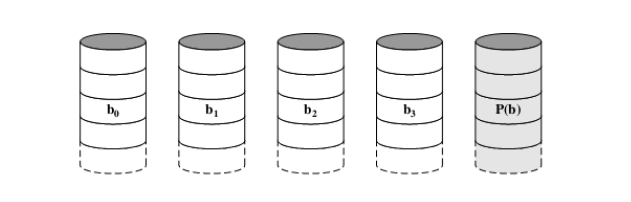
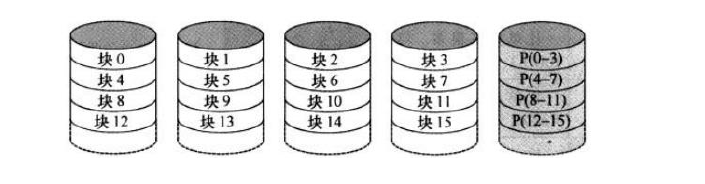
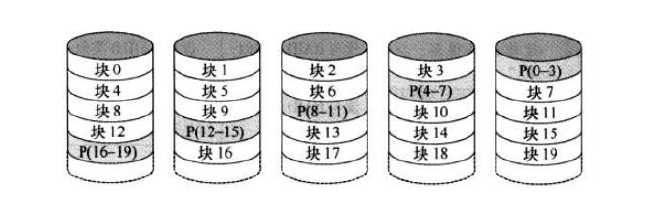
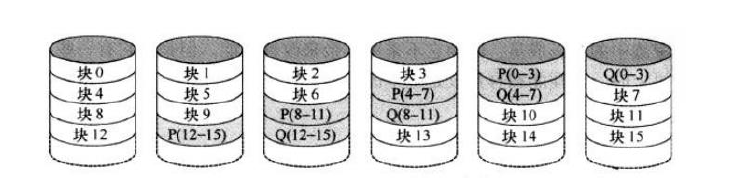
可靠性分析:


12 虚拟存储器
分区方式
分区方式将主存分为两大区域
- 系统区:固定的地址范围内,存放操作系统
- 用户区:存放所有用户程序
简单固定分区
用户区划分成长度不等的固定长的分区
当一个任务调入主存时,分配一个可用的、能容纳它的、最小的分区
优点:简单
缺点:浪费主存空间
可变长分区
用户区按每个任务所需要的内存大小进行分配
优点:提高了主存的利用率
缺点:时间越长,存储器中的碎片就会越多
分页式
把主存分成固定长且比较小的存储块,称为页框(page frame)每个任务也被划分
成固定长的程序块,称为页(page)
将页装入页框中,且无需采用连续的页框来存放一个任务中所有的页
内存的大小是有限的,但对内存的需求不断增加
[!NOTE]
请求分页:
仅将当前需要的的页面调入主存;通过硬件将逻辑地址转换为物理地址,未命中时在主存和硬盘之间交换信息
优点:
- 在不扩大物理内存的前提下,可以载入更多的任务
- 编写程序时不需要考虑可用物理内存的状态,程序员认为可以独享一个连续的、很大的内存
- 可以在大于物理内存的逻辑地址空间中编程
[!TIP]
Cache比主存快 10 倍,主存比硬盘快 100000 多倍
因此应当尽量提高命中率
关联映射+写回
页表,TLB

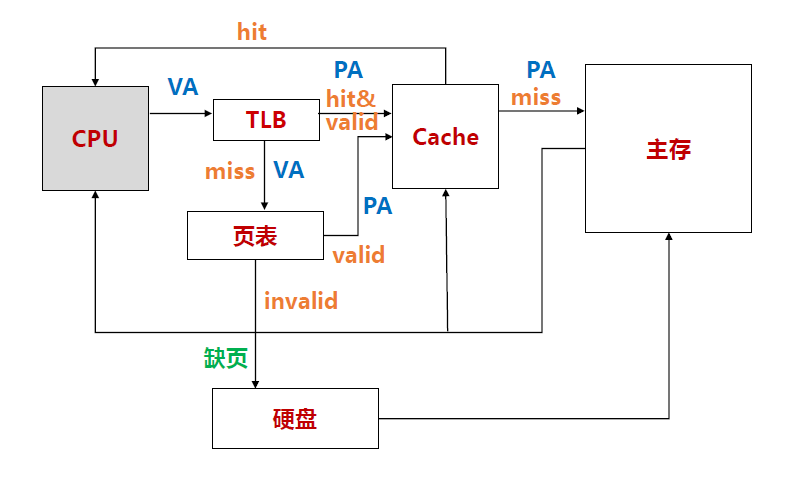
页表缺失时TLB、Cache必定缺失,页表缺失时Cache和TLB的缺失无关联
虚拟存储器
分页式虚拟存储器:
优点:实现简单,开销少
缺点:数据可能跨页面
分段式虚拟存储器:将程序和数据分成不同长度的段,将所需的段加载到主存中
虚拟地址:段号 + 段内偏移量
优点:段的分界与程序的自然分界相对应,易于编译、管理、修改和保护
缺点:段的长度不固定
段页式虚拟存储器:将程序和数据分段,段内再进行分页
优点:程序按段实现共享和保护
缺点:需要多次查表
习题7
存储综合大题
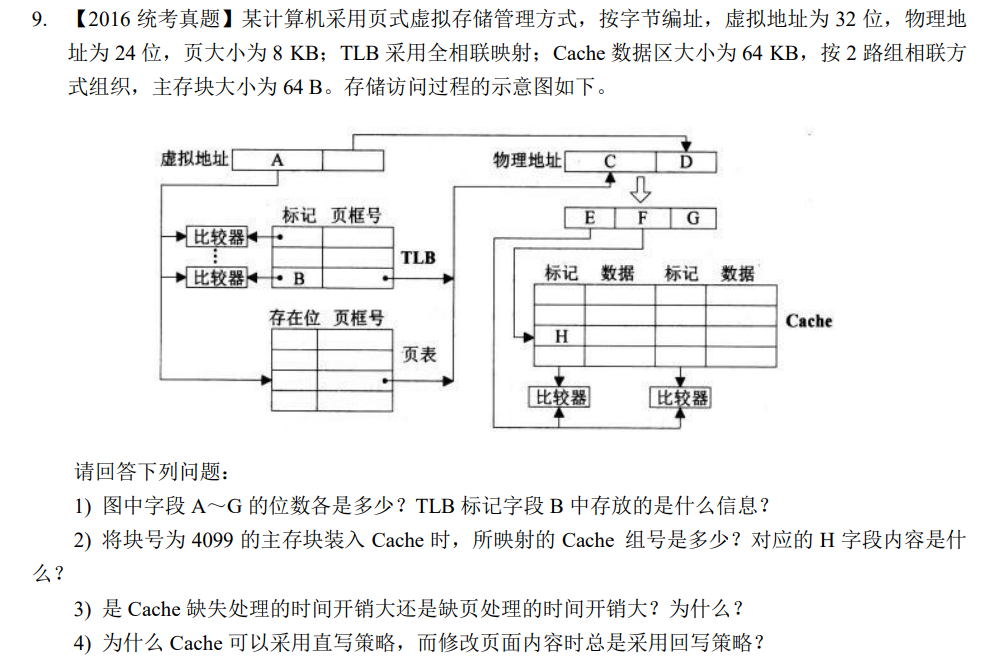

存储综合
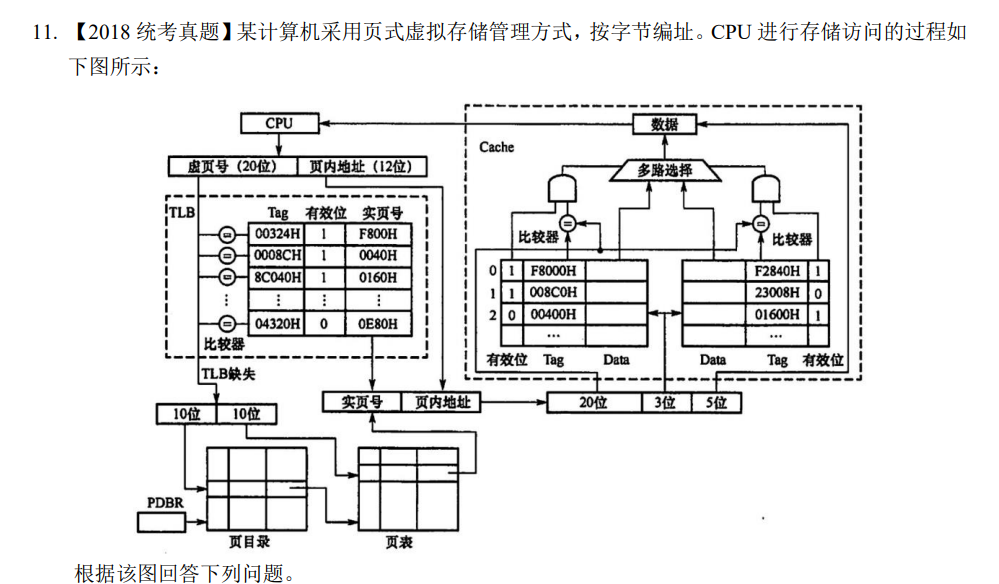


13 指令系统
寻址方式
立即寻址 操作数=A
直接寻址 EA=A
间接寻址 EA=(A)
寄存器寻址 EA=R
寄存器间接寻址 EA=(R)
偏移寻址 EA=(R)+A
相对寻址:EA=(PC)+A
优点:利用程序局部性原理,节省指令中地址的位数
用法:大多数存储器访问都靠近正在执行的指令
基址寄存器寻址:EA=(B)+A
用法:虚拟内存空间的程序重定位
变址寻址:EA=A+(R)(前两者以A作为偏移量,这里以寄存器作为偏移量)
用法:为完成重复操作提供一种高效机制
扩展:前变址EA=(A+(R));后变址EA=(A)+(R);基址带变址寻 址EA=A+(B)+(R)
栈寻址:栈指针保存在寄存器中,实际上是寄存器间接寻址方式
14 指令周期和指令流水线
指令周期:处理单个指令的过程
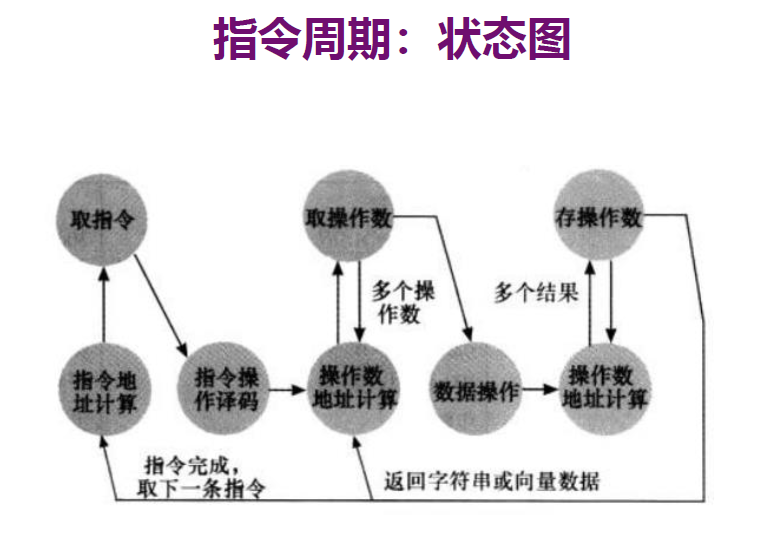
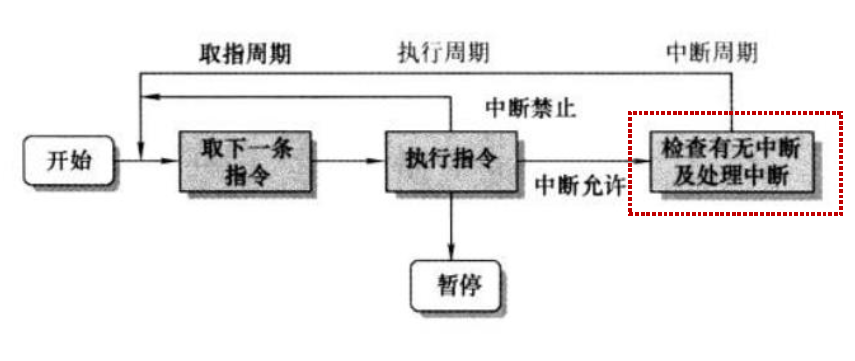
间址周期
指令的执行可能涉及一个或多个存储器中的操作数,它们每个都要求一次存储器访问
间址周期:把间接地址的读取看成是一个额外的指令子周期
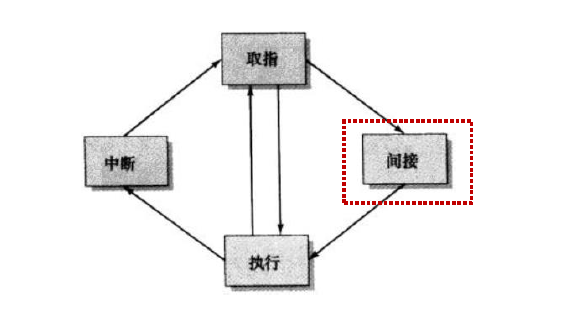
指令流水线:一条指令的处理过程分成若干个阶段,每个阶段由相应的功能部件完成
两阶段方法:取指令和执行指令
问题:执行时间一般长于取指时间;主存访问冲突;条件分支指令
六阶段方法
问题:
不是所有指令都包含六个阶段,如LOAD没有WO,只能假设每个指令按六阶段完成;
不是所有阶段可以并行完成,如FI、FO、WO都涉及存储器访问;若每个阶段时间不同,则会涉及等待
限制:
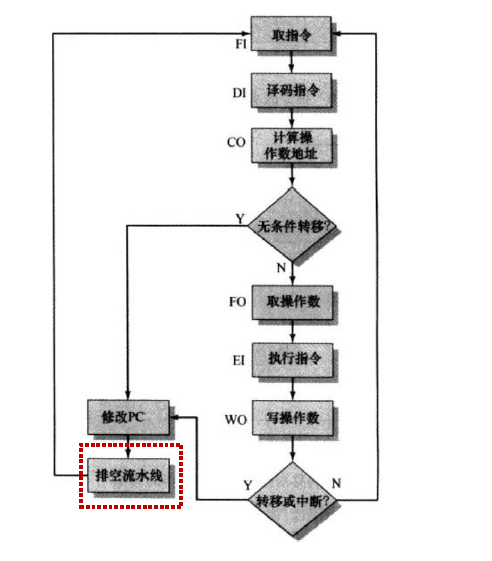
条件分支指令
中断

流水线阶段数提高的局限:
每个阶段转移数据存在开销;
处理内存和寄存器依赖以及优化管道所用的控制逻辑数量随着阶段的增加而增加
流水线性能分析


流水线冒险
在某些情况下,指令流水线会阻塞或停顿(stall),导致后续指令无法正确执行
结构冒险:硬件资源冲突
问题:已进入流水线的不同指令在同一时刻访问相同的硬件资源
解决:使用不同的硬件资源;或分时访问同一资源
数据冒险:数据依赖性
问题:未生成指令所需要的数据
解决:插入 nop 指令;插入 bubble;转发/旁路;交换指令顺序
控制冒险:指令顺序被更改
问题:条件转移、中断、异常、调用/返回
解决:
取多条指令:多个指令流;预取分支目标;循环缓冲器
分支预测:
静态预测;动态预测:转移状态图;转移历史表
15 控制器
寄存器分类
用户可见寄存器:
类型:通用寄存器、数据寄存器、地址寄存器、条件码寄存器/标志寄存器
寄存器的数量能不能无限增加:
太少的寄存器会导致更多的存储器访问
太多的寄存器又不能显著减少存储器访问
寄存器的长度:应能保存大部分数据类型的值;某些机器允许两个相邻寄存器合并
保存和恢复:子程序调用时作为CPU的责任,其余时候作为程序员的责任
控制和状态寄存器:
例子:PC、IR、MAR、MBR、PSW
其他机器上可能存在的:指针寄存器、中断向量寄存器、系统栈指针、页表指 针寄存器、控制地址寄存器、控制缓存寄存器
设计的出发点:对操作系统的支持;控制信息在寄存器和存储器之间的分配(在成本和速度间权衡)
微操作
微操作分组的原则:事件流动顺序恰当、避免冲突、时间尽可能少
取指、间址、中断周期各有一个微操作序列,执行周期则对于每个操作码有一个微操作序列
CPU的基本元素:ALU、寄存器组、内部数据通路、控制器、外部数据通路
CPU需要完成的微操作:
- 在寄存器间传送数据
- 将数据从寄存器传送到外部接口(如总线)
- 将数据从外部接口传送到寄存器
- 将寄存器作为输入和输出,完成算术和逻辑运算
控制器
基本任务:定序、执行
输入:
- 指令寄存器:当前指令的寻址方式和操作码
- 标志:确定CPU的状态和前一个ALU操作的结果
- 时钟:控制器要在每个时钟脉冲完成一个或一组微操作
- 来自控制总线的控制信号:向控制器提供控制信号
输出:
- CPU内的控制信号:用于寄存器间传输数据;用于启动特定ALU功能
- 到控制总线的控制信号:到存储器的控制信号;到I/O模块的控制信号
实现:
硬布线实现:
- 构成:指令寄存器、译码器、定时器、控制器
- 优点:速度较快
- 缺点:硬件设计较为复杂
微程序实现:
微指令的设计考虑:
微指令的大小:微指令越小控制器存储成本越低
地址生成时间:尽可能快地执行微指令
微指令类型:双地址字段;单地址字段;可变格式
构成:定序逻辑、控制地址寄存器、控制存储器、控制缓冲寄存器
优点:简化了控制器的设计任务;实现起来成本较低且出错机会减少
缺点:比硬布线控制器慢
习题8
指令格式

变址寻址

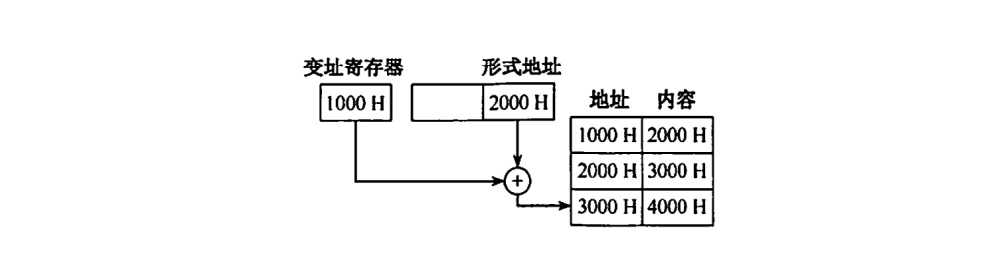
变址寻址

微程序编码


概念

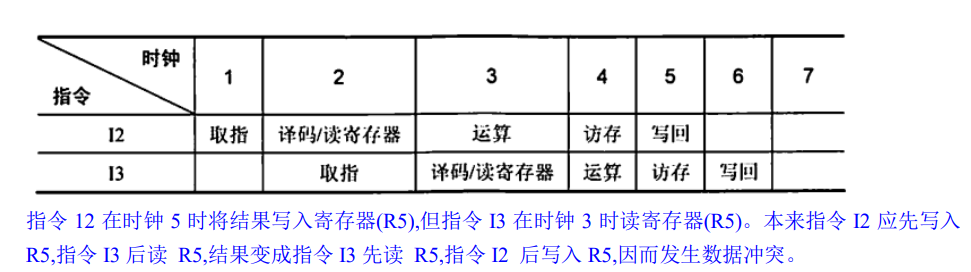
数据冒险

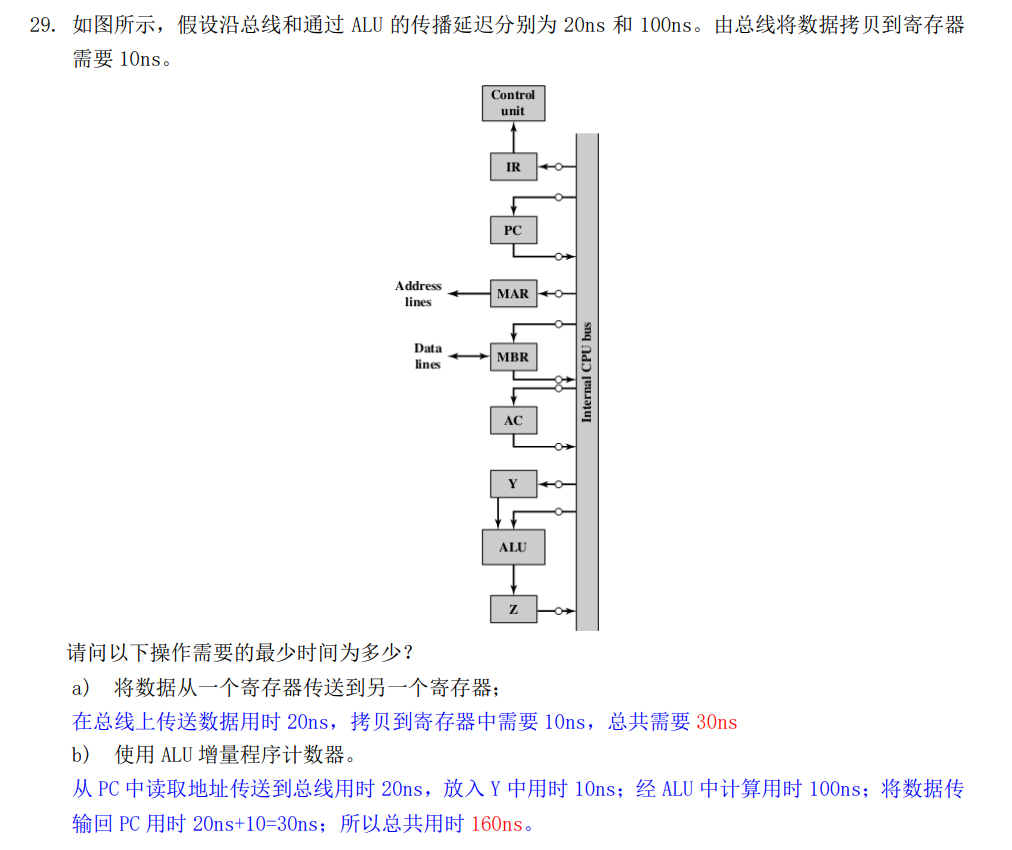
计算
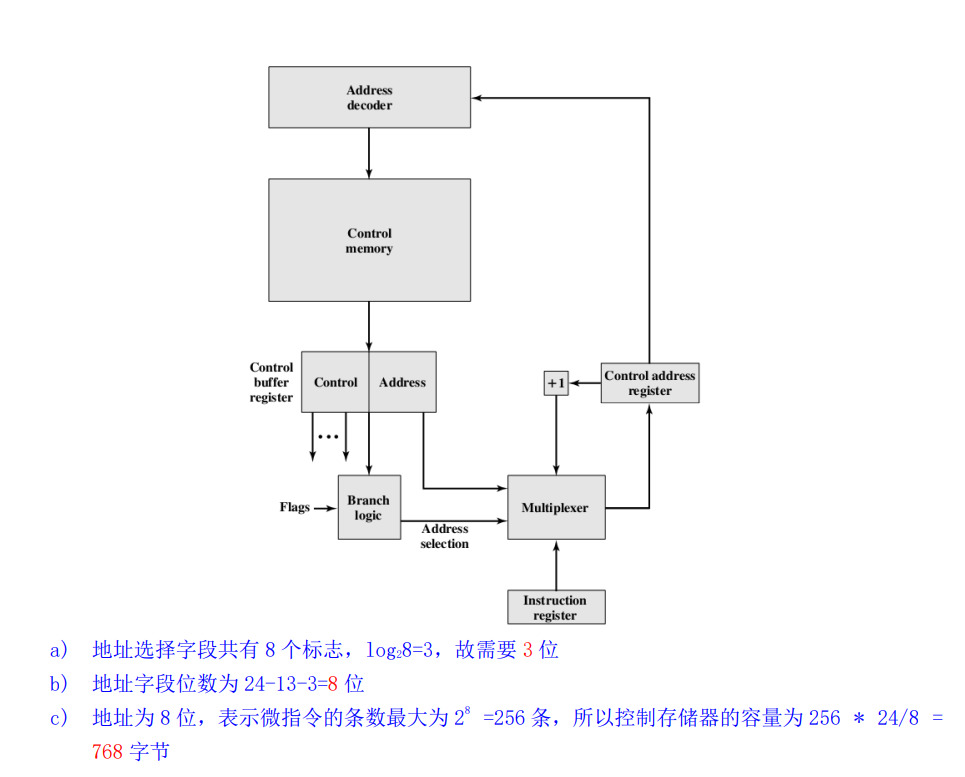
微操作编码

考过

16 总线
总线的用途:
专用总线:
优点:高吞吐量,减少总线冲突
缺点:增加了系统的规模和成本
复用总线:
优点:布线少,节省空间和成本
缺点:需要更复杂的控制电路,且共享可能会降低性能
总线仲裁
总线仲裁的平衡因素:
优先级:优先级高的设备优先被服务
公平性:优先级低的设备不能一直被延迟
集中式的仲裁方案:
链式查询(菊花链):
优点:确定优先级很简单;可以灵活添加设备
缺点:不能保证公平性;对电路故障敏感;限制总线的速度
计数器查询:
优点:通过使用不同的初始计数,灵活地确定优先级;对电路故障不敏感
缺点:需要添加设备ID线;需要解码和比较ID信号;限制总线的速度
独立请求:
优点:快速响应;可编程的优先级
缺点:复杂的控制逻辑;更多的控制线路
分布式的仲裁方案:
自举式
冲突检测
总线的时序:
同步时序:
优点:更容易实现和测试
缺点:所有设备共享一个时钟;总线长度受到时钟偏差的限制
异步时序:
优点:可以灵活地协调速度不同的设备
缺点:接口逻辑复杂(三次握手);对噪声敏感
半同步时序:结合了同步时序和异步时序的优点
分离事务:
优点:增加总线利用率
缺点:增加每个总线事务的持续时间和系统复杂度
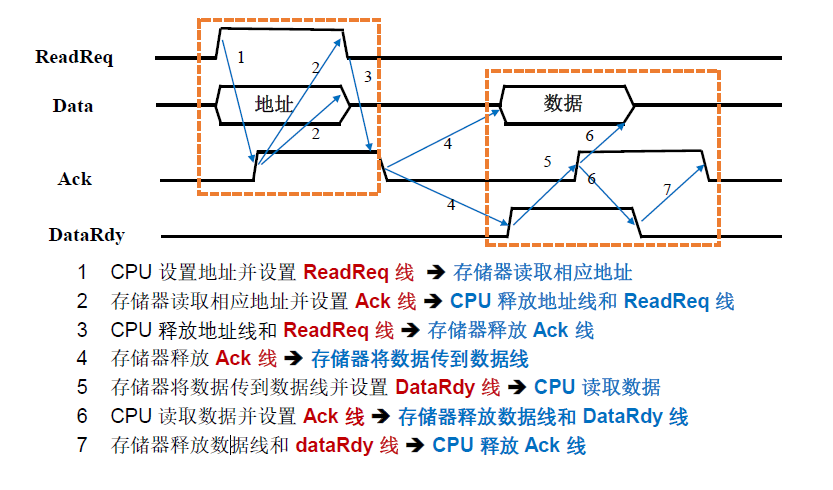
异步时序七次握手
总线带宽、数据传输速率

习题9
总线标准

突(猝)发传输


误区

DDR

注意同步总线对齐时钟周期


17 输入输出
为什么外设不能直接连到系统总线上:
- 外设种类繁多,操作方法多种多样;
- 外设的数据传送速度一般比存储器和处理器慢得多;
- 某些外设的数据传送速度比存储器和处理器快;
- 外设使用的数据格式和字长通常和处理器不同
I/O 模块功能
- 处理器通信:命令译码、传送数据、状态报告、地址识别
- 设备通信:包含命令、状态信息和数据
- 数据缓冲:解决速度差异问题
- 控制和定时
- 检错:设备报告的故障和传输过程中数据位的变化
I/O操作技术:
编程式I/O:
- 中断:无中断,需要100%占用CPU
- I/O命令:控制命令、测试命令、读命令、写命令
- I/O指令:编址方式:存储器映射式I/O、分离式I/O
中断驱动式I/O:
- 中断:有中断
- 中断时保存与恢复:PC、PSW、通用寄存器、掩码字
- 响应优先级和处理优先级:掩码字矩阵
设备识别方式:
- 轮询:轮询次序决定优先级
- 菊花链:模块连接顺序决定优先级
- 独立请求:中断控制器决定优先级
- 多条中断线:和前面三者结合,仅挑选优先级最高的中断线
与处理器连接的I/O方式的不足:
I/O速度受处理器测试和服务设备速度的限制;处理器负责管理I/O传送,对于每一次I/O传送,处理器必须执行很多指令
DMA
组成:数据计数、数据寄存器、地址寄存器、控制逻辑
内存访问策略:
CPU停止法:
优点:控制简单
缺点:影响CPU,没有充分利用内存
适用:高速I/O设备的块传输
周期窃取法:
优点:充分利用CPU和内存,及时响应I/O请求
缺点:DMA每次都请求总线
适用:I/O周期大于存储周期
交替分时访问法:
优点:CPU未停止或等待,DMA不请求总线
缺点:CPU周期可能大于存储周期
配置机制:
单总线分离式:DMA使用编程式I/O,所有模块共用总线,便宜但低效
单总线集合的DMA-I/O:DMA可能是I/O模块的一部分也可能是控制I/O 模块的单独模块;减少总线周期数
I/O总线式:多个I/O模块共享DMA,且易于扩展
I/O模块的演变:
CPU直接控制外设——编程式I/O——中断——DMA——I/O通道:I/O模块有内部的处理器和为I/O操作定制的指令集——I/O处理器:有一个局部存储器
习题10
中断屏蔽字

中断

DMA

DMA
